Exfiltration
Category: Forensic
Points: 257
Description: Notre SoC a détecté qu'un document confidentiel avait été exfiltré ! La méthode utilisée ne semble pas avancée et heureusement, une capture réseau a pu être faite au bon moment... Retrouvez ce document.
Files: Exfiltration.pcap
TL;DR
A document has been extracted via a POST requests. A xor on the recovered file allows us to read the flag in a word document.
Methodology
When we open the file with wireshark we appreciate that there are 27242 packages to look at!

So that... Let's go!
When flying over the packets we notice that there is a lot of TCP flow.

By going through all the TCP flows we obtain several interesting exchanges of the same type:

What we are interested in is this message:
<h1>Welcome to my panel!</h1>
<p>If you see this page, the malware is successfully installed and
working. No further configuration is required.</p>And the fact that requests are made via the POST method with data passes to the form's face:
data=3528706771637b6b6d63b9c7f82d736365637363656373636563786365632c11000f004c4b1116&uuid=80cxgrf7ws5phwlb7z3q
With each request the data parameter changes but not the uuid. The uuid must be a unique identifier to allow the remote server to reconstitute the exfiltered file via the data field.
A little python script to get all these packages and assemble them.
>_ cat extract.py#!/usr/bin/env python3
from scapy.all import *
import binascii
packets = rdpcap('exfiltration.pcap')
data = ''
for packet in packets:
if packet[IP].dst == '198.18.0.10' and packet[IP].src == '192.168.1.26':
if Raw in packet:
p = str(packet[Raw].load.decode("UTF-8"))
p = p.split("&uuid")[0]
p = p.split('data=')[1:]
if p:
p = p[0]
data += p
print(data)
file = open("out.txt", 'wb')
file.write(binascii.unhexlify(data))>_ ./extract.py
>_ file out.txt
out.txt: dataUnfortunately the extracted file is unreadable.
Fortunately, when designing the script I forgot to filter only on packets that contained raw data (the Raw field). When testing it, it would crash as soon as a packet did not contain the Raw field. I noticed that the packet in question was an ICMP packet with interesting data: config : exfiltered_file_size=4193bytes
To know more about it, we filter in wireshark on ICMP packets:
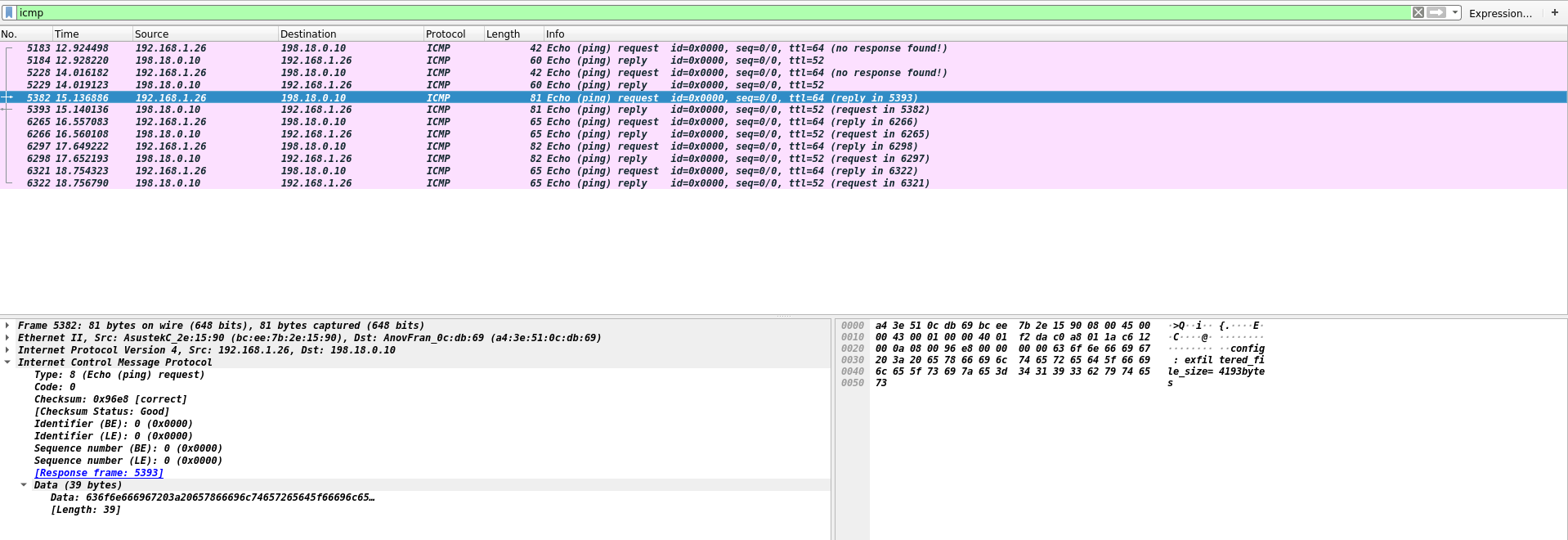
And we get four interesting facts:
config : exfiltered_file_size=4193bytes
config : file_type=DOCX
config : data_len_for_each_packet=random
config : encryption=XORThe file is 4193 bytes long, so all the data has been extracted from the packages.
>_ ls -l out.txt
-rw-r--r-- 1 lambdhack users 4193 May 22 20:06 out.txtNow we know that the exfiltered file is a word document and the encryption used is an xor. To find the key again we will xor the firsts bits of the file with the magic number of the document words. A little tour on File signature table to find the magic number of a docx.

After having done an xor, we find the key which is ecsc of course !
Now we xor this key on all the file to find the original docx.
>_ cat xor.py#!/usr/bin/env python3
import binascii
def xor(file1_b, key):
file_size = len(file1_b)
key_size = len(key)
xord_byte_array = bytearray(file_size)
key_pad = key
for i in range(file_size):
key_pad += key
# XOR between the files
for i in range(file_size):
xord_byte_array[i] = file1_b[i] ^ key_pad[i]
open('data.docx', 'wb').write(xord_byte_array)
if __name__ == '__main__':
key = 'ecsc'.encode()
data = open('out.txt', 'rb').read()
xor(data, key)>_ file data.docx
data.docx: Microsoft Word 2007+The file has been well deciphered.

FLAG_IS:
ECSC{v3ry_n01sy_3xf1ltr4t10n}